
[HPC] 엑사급 초고성능컴퓨터를 위한 오토튜닝 프레임워크 개발
엑사급(Exascale) 초고성능 컴퓨터(HPC)는 1초에 10의 18제곱 연산을 처리할 수 있는 슈퍼컴퓨터입니다. 주로 과학 시뮬레이션, 인공지능 학습, 기후 예측 등 방대한 계산 자원이 필요한 분야에서 활용됩니다. 하지만 거대한 시스템을 효율적으로 활용하기 위해서는 각기 다른 하드웨어 자원과 복잡한 소프트웨어 환경을 상황에 맞게 최적화하는 것이 매우 중요합니다. KISTI 슈퍼컴퓨팅 센터와 협업하여 슈퍼컴퓨터 5호기(누리온 등), 6호기에 효과적인 스케줄링 알고리즘과 프로그램 실행 시 파라미터를 자동으로 튜닝하는 기법을 제안합니다.
HPC 스케줄링 최적화를 위한 기계학습(강화학습) 알고리즘 연구
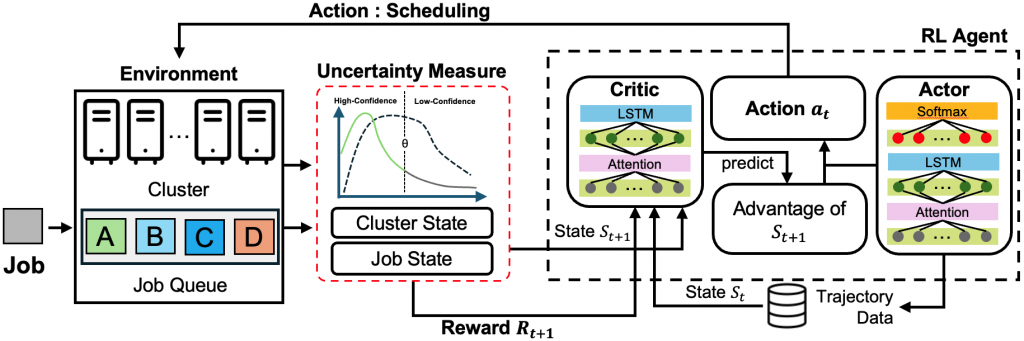
슈퍼컴퓨터(i.e., 고성능컴퓨팅 클러스터)의 성능을 극대화하기 위해서는 멀티 노드에서의 작업 스케줄링이 필수적입니다. 이러한 클러스터 환경은 제출된 작업 처리율, 대기 시간, 자원 활용률 등 최적화가 필요한 변수들이 있습니다. 기존의 heuristic or rule 기반 스케줄러(FCFS, SJF 등)는 갑작스런 시스템 구성 변화에 동적으로 대응하지 못하고 새로운 워크로드 특성에 맞춰 자원 할당이 어려운 문제가 있습니다. 이에 따라 새로운 대안으로 인공지능 기반 다양한 스케줄링 기법이 제안되고 있습니다. 그 중, 강화학습은 명시적인 규칙 없이도 동적으로 스케줄링 정책을 학습할 수 있도록 구성하여 기존 연구들에서 좋은 결과를 보이고 있습니다.
따라서, 본 프로젝트는 동적인 환경에 적절히 대응함과 동시에 여러 지표를 최적화 가능한 스케줄링 알고리즘을 연구하고자 합니다. 현재 환경에 맞게 여러 지표 간 우선순위를 자동으로 정의한 뒤, 강화학습 정책을 통해 스케줄링을 수행하는 것입니다. 예를 들어, 성능 지표는 평균 작업 대기 시간, 처리율, 자원 활용률 등 여러 지표들이 좋은 성능을 보이도록 기계학습 혹은 강화학습 기반의 알고리즘을 활용하여 새로운 기법을 제안합니다.
다차원 쿼리 처리를 위한 경량 LSM-Tree 인덱싱 기술 개발

IoT 디바이스, 모바일 어플리케이션, 그리고 대규모 언어 모델(LLM) 기반 서비스의 확산으로 데이터가 폭발적으로 생성되는 현대 컴퓨팅 환경에서, 대용량 데이터를 고속으로 수집하는 것뿐만 아니라 즉각적으로 분석하는 능력은 필수적입니다. 이를 위해 많은 시스템이 쓰기 성능이 뛰어난 LSM-Tree (Log-Structured Merge Tree) 기반의 데이터베이스를 채택하고 있습니다. 그러나 기본 키 조회에 최적화된 LSM-Tree의 구조적 특성상, “특정 리전의 20대 사용자 활동 로그”와 같이 여러 속성을 조합해야 하는 다차원 쿼리(Multidimensional Query) 처리 시에는 전체 데이터를 탐색해야 하는 심각한 읽기 성능 저하가 발생합니다.
우리 연구실은 이러한 문제를 해결하고자, LSM-Tree의 고속 쓰기 성능을 온전히 보존하면서도 다차원 분석 쿼리를 획기적으로 가속화할 수 있는 인덱싱 기술을 연구하고 있습니다. 이 기술은 인덱스의 생명주기를 불변 데이터 파일(SSTable)과 일치시켜 인덱스 관리 오버헤드를 낮추고, 비트맵 연산을 통해 복잡한 다차원 조건의 데이터를 효율적으로 필터링할 수 있도록 합니다.
특히, 데이터 분포에 따라 인덱스를 적응적으로 최적화하는 기법을 도입하여, 데이터 분포의 편향이 심한 환경에서도 일관된 분석 성능을 보장하는 것을 핵심 목표로 하고 있습니다. 이를 통해 고속의 데이터 수집과 지연 없는 실시간 분석이 동시에 요구되는 차세대 데이터 플랫폼의 핵심 스토리지 엔진 기술을 확보하고자 합니다.
[MD-GNN] Multi-GPU 환경에서 GNN 기반의 MLIP 최적화 기법 연구
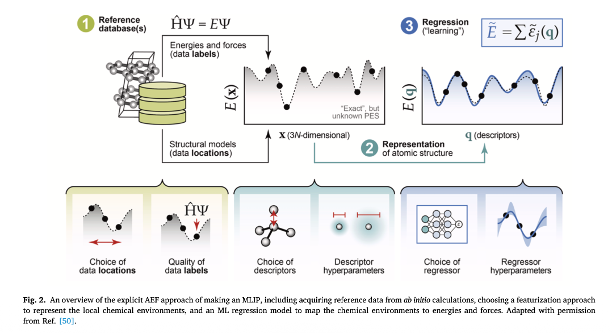
MD (Molecular Dynamics, 분자동역학)는 원자의 위치와 속도를 시간에 따라 적분하여, 물질의 동역학적 움직임을 계산하는 시뮬레이션 기법입니다. MD는 양자역학 기반의 QM (Quantum Mechanical Electroninc Structure Calculations)에 비해 계산 비용이 현저히 낮아 대규모 시스템에서 활용이 가능하며 CM (Continum Model)과 달리 원자 수준의 미시적 구조를 직접 시뮬레이션이 가능하기 때문에 재료공학, 화학공학 등 다양한 분야에서 활발히 사용되고 있습니다.
MD 시뮬레이션에서는 원자 간 상호작용을 퍼텐셜 에너지 함수(Force Field 또는 Interatomic Potential)로 근사하여, 각 원자에 작용하는 힘을 계산하여 이를 기반으로 적분합니다. 이때 퍼텐셜 에너지를 계산하기 위한 방법 중 하나로 GNN에 기반한 Machine Learning 기법이 최근 빠르고 높은 정확성으로 주목받고 있습니다.
GPU 환경 특화 MD 시뮬레이터 프레임워크 개발
LAMMPS, GROMACS와 같은 전통적인 MD 시뮬레이터는 CPU 중심의 실행 모델을 기반으로 설계되어 GPU는 주로 Force 계산과 같은 일부 역할을 가속하는 역할에 한정되어 있습니다. 이러한 구조에서 neighbor list 생성, 데이터 재배치, 통신 제어 등 다수의 단계가 여전히 CPU에 의존하게 되어, 이로 인해 CPU-GPU 간 통신 병목과 GPU Idle time이 발생합니다. 또한, CPU와 동일한 원자 데이터가 중복 저장됨으로써 메모리 사용 효율 또한 저하됩니다.
이러한 구조적 한계를 근본적으로 해결하기 위해, GPU를 주 실행 장치로 설정한 GPU-specific MD 시뮬레이터 프레임워크를 KISTI와 협업하여 개발하고 있습니다. 해당 프레임워크는 MD 시뮬레이션의 주요 계산 및 데이터 흐름을 GPU-resident 방식으로 통합함으로써, 대규모 시스템과 GNN 기반 MLIP을 포함한 복잡한 force 계산에서도 높은 성능 확장성을 달성하는 것을 목표로 합니다.
Pipelining을 통한 GNN-IP 최적화 기법 개발
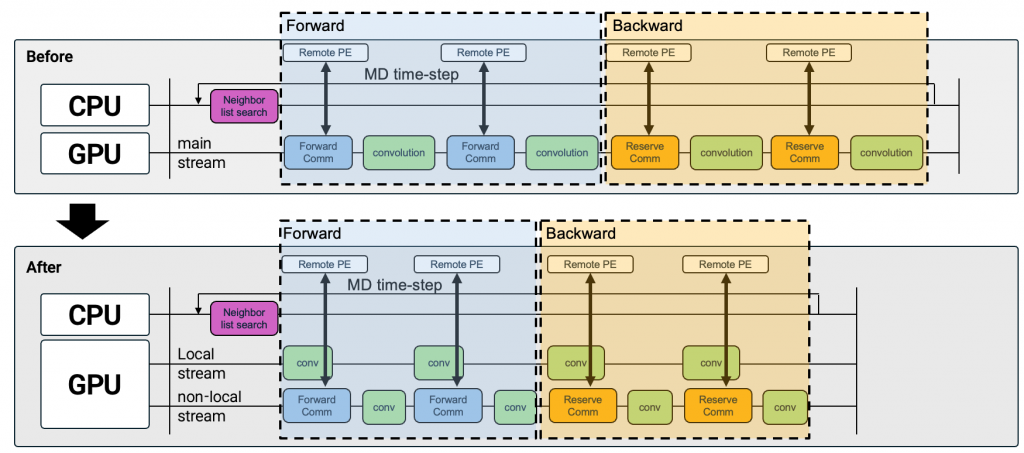
LAMMPS와 GROMACS와 같은 heterogeneous 하드웨어 기반 MD 시뮬레이터에서 GNN-IP를 효율적으로 가속하기 위해, GPU 상의 local 계산과 non-local 통신을 분리하고 이를 overlap하는 pipelining 기법을 연구하고 있습니다. GNN의 forward 및 backward 단계에서 halo atom exchange 통신이 발생되는 convolution 연산을 non-local GPU 스트림으로 분리하고, 이를 local convolution 연산과 동시에 수행함으로써 통신 지연을 은닉한다. 이를 통해 기존의 직렬 실행 구조 대비 GPU 자원 활용도를 향상시키고, GNN-IP 기반 MD 시뮬레이션의 시간당 처리 성능을 개선하고자 합니다.
[Big Data] 자율주행 차량의 대용량 주행 시나리오 질의 웹 페이지 개발
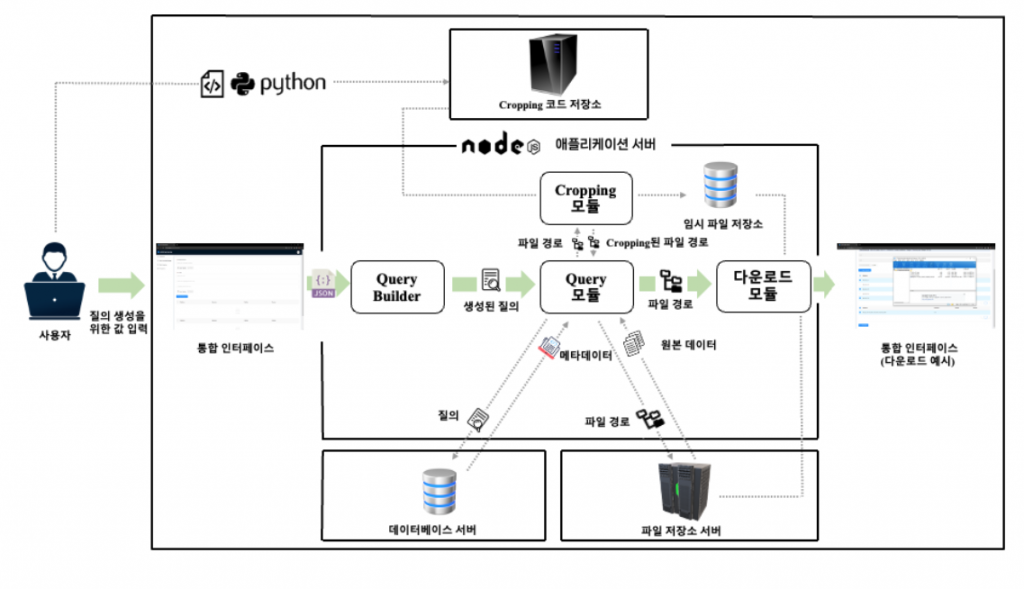
아주대학교 미래모틸리티학과(기계공학과) 연구실과 협업하여 진행하는 프로젝트로, 100TB 규모의 자율주행 차량 주행 데이터를 효과적으로 관리하고 활용하는 데이터 서비스 플랫폼을 개발하고 있습니다. 사용자가 웹 인터페이스를 통해 복잡한 데이터를 쉽게 질의하고, 맞춤형 분석을 요청할 수 있으며, 빠르고 정확한 결과를 받아볼 수 있는 시스템을 구축하는 것이 목표입니다. 이를 위해 대용량 데이터 환경에서 효율적인 저장 구조, 실시간 쿼리 처리, 사용자 요청에 최적화된 응답 시스템 등 다양한 기술적 과제에 대한 연구를 함께 수행하고 있습니다.
기존의 Hadoop MapReduce 기반 배치 데이터 처리 방식을 Spark 기반의 병렬 처리 방식으로 재설계할 계획입니다. In-memory 방식을 활용한 Spark 기반 설계를 통해 기존 방식 대비 처리 시간을 50% 이상 단축하는 것을 목표로 합니다. 또한, 데이터 읽기/쓰기 속도 최적화를 위해 MongoDB의 WiredTiger 엔진과 RocksDB를 결합한 하이브리드 환경을 구축할 예정입니다. 이 구조에서는 데이터베이스 라우터를 통해 읽기와 쓰기 작업을 분리하고, 데이터 일관성을 유지하기 위한 동기화 메커니즘을 적용할 계획입니다.
데이터 전송 효율성 향상을 위해 스트리밍 기반 다운로드 방식을 도입하여 파일 전송 구조를 고도화할 계획입니다. 기존의 파일 복사 과정을 제거함으로써 디스크 I/O를 최소화하고, 파일 압축 및 전송 과정을 스트리밍 방식으로 연동하여 전체 다운로드 시간을 단축하고자 합니다. 또한 실시간 전송 환경에서 데이터 무결성을 보장하기 위해 MD5 해시 기반의 검증 체계를 구축하여 안전한 데이터 전송을 가능하게 할 예정입니다.
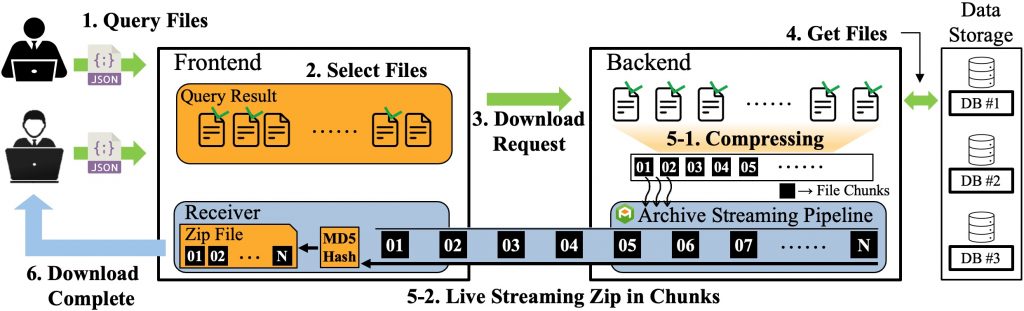
우리 연구실에서는 데이터 플랫폼 서비스 제공을 위해 필요한 연구를 수행하고, 그 연구 결과를 실제 서비스에 도입하여 검증합니다. 백엔드 엔지니어링 관점에서 마이크로 서비스, 분산 아키텍처, 메세징 시스템, 분산 큐 등 구현이 필요한 요소를 Kafka, RabbitMQ 등 분산 환경에서 주로 활용되는 프레임워크/라이브러리를 도입하여 해결하고자 합니다. 이 과정에서 발생 가능한 기술적인 한계를 극복하기 위해 시스템 부하 분산, 장애 복구, 데이터 일관성 유지 방안 등에 대한 연구도 병행할 계획입니다. 특히 대용량 데이터 처리 환경에서의 성능 최적화와 확장성 확보를 위한 아키텍처 설계에 중점을 두어 안정적이고 효율적인 데이터 플랫폼 구축을 목표로 합니다.
[LLM Inference] 대규모 언어모델(LLM) 운영을 위한 Inference 최적화 연구
ChatGPT 같은 LLM 서비스는 한 사용자의 답변을 만들 때 문장을 한 번에 완성하는 것이 아닌, 토큰(문장을 잘게 나눈 조각)을 하나씩 순차(iteration)적으로 생성합니다. 그리고 다수의 사용자 요청에 대응하기 위해서 서버는 동시에 들어오는 여러 요청들을 묶어 한 번에 실행(배치 처리)해 GPU 자원을 효율적으로 사용해야 합니다. 이때 어떠한 요청들을 언제, 얼마나 묶어서 실행할지를 정하는 것이 Scheduling for LLM Inference이며, 토큰 생성 과정에서 생기는 KV Cache(중간 계산 결과를 저장하는 메모리, 캐시)까지 함께 고려해야 실제 서비스 수준에서 안정적인 성능을 낼 수 있습니다.
LLM Inference Scheduling 기반 LLM 서빙 최적화
 운영을 위한 Inference 최적화 연구")
LLM 서빙에서 스케줄링은 매 토큰 생성 단계에서 어떤 요청들을 골라 같이 묶어서 배치로 처리할지를 정하는 문제입니다. 예를 들어 동시에 100명이 답변을 기다리고 있다면, 서버는 그 요청들 중 일부를 뽑아 한 번에 계산하고, 다음 iteration에는 또 다른 조합으로 묶어서 처리합니다. 이 배치 선택 방식에 따라 어떤 사용자는 빠르게 응답을 받기도 하고, 어떤 사용자는 불필요하게 오래 기다릴 수도 있으며, GPU를 full-load 시킬 수도, 비효율적으로 놀게 할 수도 있습니다.
특히 실제 서비스 환경에서는 요청이 항상 일정하지 않습니다. 어떤 시간대에는 짧은 질문들이 몰릴 수 있고, 또 어떤 시간대에는 긴 요청(프롬프트 및 답변이 긴 요청)이 많아질 수도 있습니다. 동시에 새로운 사용자들의 요청은 계속 들어올 것이며, 이미 처리 중인 요청들도 고려해야 합니다. 이러한 상황에서 고정된 규칙(예: 무조건 N개씩 묶기 등)만으로는 워크로드(요청 빈도, 길이 등) 변화에 유연하게 대응하기가 어려우며, 갑자기 사용자가 대기하는 시간이 길거나, 처리량이 급격히 떨어지는 현상이 발생할 수 있습니다.
우리 연구실에서는 이러한 문제를 해결하고자 LLM 서빙에서 i) 어떤 요청을 먼저 선택할지(우선순위 판별), ii) 한 번에 몇 개를 어떤 단위로 묶을지(동적 배치 구성), iii) GPU 자원을 어떻게 배분할지(GPU 자원 할당) 같은 요소들에 대해서 연구를 진행 중입니다. 연구의 핵심 목표는 요청 처리량(throughput)을 최대화 시키는 동시에 처리 지연(latency)를 최소화 시키는 스케줄링 정책을 설계하는 것입니다.